
毎朝ダッシュボードが自動更新されて、チーム全員がそれを見て動く
そういう定型のデータ分析基盤を作るとき、Amazon Redshiftは頼れる選択肢となります。
GlueやAthenaと並んでAWSのデータ分析レイヤーでよく登場するサービスですよね。
でも、
Athenaと何が違うの?
どういうときにRedshiftが最適なの?
という疑問が、使ったことがないと浮かんでくるかもしれません。
そこでこの記事では、Redshiftが何者なのか・他のサービスとの使い分け・料金・設定の流れを、ざっくりまとめます。
これからRedshiftを使い始めようと検討されている方の参考になれば幸いです。
そもそも何ができるの?
Amazon Redshiftは、ペタバイト規模のデータを高速にSQLクエリで分析できる、フルマネージドのデータウェアハウスサービスです。
データウェアハウスとは、各システムから集めたデータを一元管理し、分析・集計に特化したデータベースのことです。
Redshiftの大きな特徴は 列指向ストレージ(カラムナーストレージ) を採用していること。
一般的なデータベースが行単位でデータを保存するのに対し、Redshiftは列単位で保存します。
例えば、「売上合計を出したい」といった集計クエリでは、必要な列だけを読み込めばよいですよね。
そのため、行単位より列単位の方がI/Oが大幅に削減されてクエリが速くなってくれるわけです。
またMPP(大規模並列処理)アーキテクチャにより、複数ノードでクエリを分散処理します。
テラバイト〜ペタバイト規模のデータでも、クエリを並列で処理することで高速な結果を返してくれるんです。
また、SQLはPostgreSQL互換なので、PostgreSQLやRDS(PostgreSQL)を使ったことがあれば、ほぼ同じ感覚で書けます。
QuickSightやTableauなどのBIツールともJDBC/ODBC経由でつなげられるため、可視化基盤としても広く使われています。
まとめると、
といった特徴になります。
なお、Redshift Spectrumという機能を使えば、S3上のデータをRedshift内のテーブルとJOINしてクエリすることができます。
たとえば「Redshiftに入っている顧客マスタと、S3に積み上がっているログを合わせて集計したい」という場面で力を発揮します。
S3のデータだけをクエリするAthenaとは違い、RedshiftとS3をまたいだ分析ができるのがSpectrumならではの使いどころです。
どんな時に使うの?
Redshiftが特に向いている用途と、向いていない用途を整理します。
Redshiftが向いているケース
Redshiftが向いていないケース
例えば、AthenaとRedshiftの使い分けをひと言でまとめると
というイメージです。
もちろん両方を組み合わせるアーキテクチャもよく使われているようです。
お金はどのくらいかかるの?
Redshiftには大きく2つの料金体系があります。
① プロビジョニング型(クラスター)
ノードを起動した時間に対して課金され、ノードタイプによって料金が異なります。
| ノードタイプ | スペック | 料金(東京・オンデマンド) |
|---|---|---|
| dc2.large | 2 vCPU / 15GB RAM / 160GB SSD | $0.314 /時間 |
| ra3.xlplus | 4 vCPU / 32GB RAM / マネージドストレージ | $1.086 /時間 |
| ra3.4xlarge | 12 vCPU / 96GB RAM / マネージドストレージ | $3.26 /時間 |
ra3系はストレージとコンピューティングが分離されており、S3ベースのマネージドストレージを使うため、データ量に応じてストレージのみスケールできます。
長期利用ならリザーブドインスタンス(1年・3年契約)を活用することにより、オンデマンドより大幅に割引されます。
② Redshift Serverless
クラスターを管理せず、クエリを実行したときだけ課金されるサーバーレス型です。
| 内容 | 料金(東京) |
|---|---|
| コンピューティング | $0.45 / RPU時間 |
| ストレージ | $0.024 / GB・月 |
RPU(Redshift Processing Unit)はRedshift Serverlessが自動でスケールする処理単位です。
クエリが来ていないときはコンピューティング費用がかかりません。
「使う頻度はそれほど高くないが、クエリが来たときは速く返したい」という場合に向いています。
試験的に使い始めるならServerlessから始めるのが手軽でオススメです。
なお、新規アカウントにはRedshift Serverlessの無料トライアル枠が提供されています。
まずトライアルで試してから導入を検討できるのはありがたいですね。
どうやって設定するの?
Redshift Serverlessを使ったシンプルな始め方を解説します。
コンソールの初回ガイドに沿って進めるだけなので、割とサクッと設定できて驚くかもしれません。
① コンソールを開いて「デフォルト設定を使用」を選ぶだけ
AWSコンソールでAmazon Redshiftを開くと、初回はセットアップガイドの画面が表示されます。
開かれなかった場合は、左側メニューから、「Redshift Serverless」をクリックしてください。
そして「設定」の下にある「デフォルト設定を使用」を選んで「設定を保存」をクリックする。
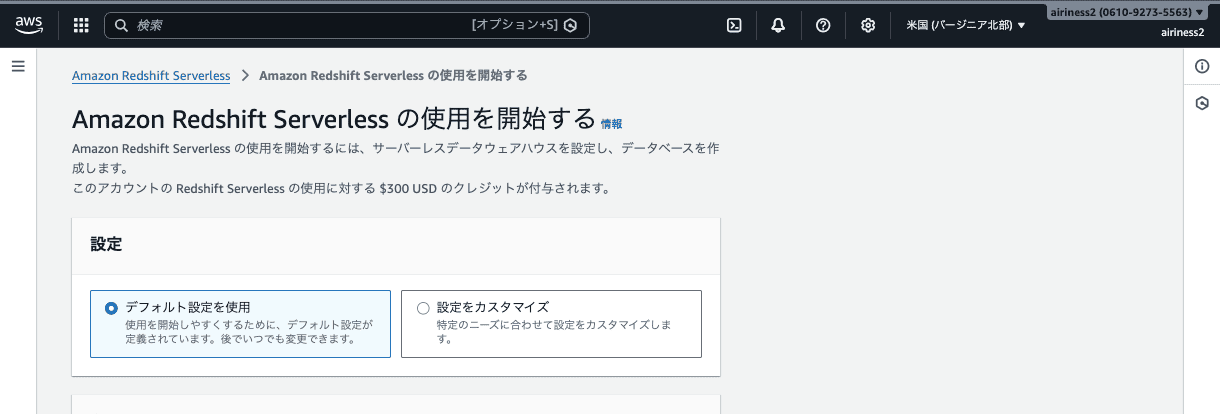
それだけで、ネームスペースとワークグループを自動で作成してくれます。
もし、細かく設定したい場合は「設定をカスタマイズ」から変更できますので試してみてくださいね。
なお、Redshift Serverlessには3つのアベイラビリティゾーンにまたがるVPCサブネットが必要です。
デフォルト設定を使った場合はデフォルトVPCがそのまま使われますが、
この条件をクリアする必要があるので、注意してくださいね。
② 「クエリデータ」からクエリエディタV2を開く
セットアップ完了後、「続行」でServerlessダッシュボードに移動します。
右上の「クエリデータ」ボタンからクエリエディタV2を起動できます。

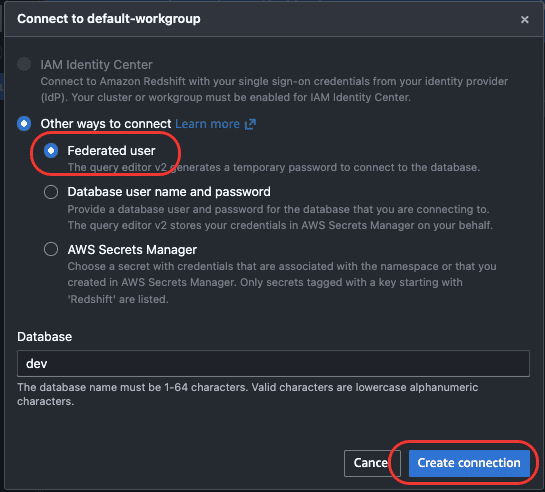
左側のツリーパネルにワークグループが表示されるので、クリックして接続してください。初回接続時は認証方式を選ぶ画面が出ます。
「Federated user」のまま「Create connection」でOKです。
③ S3からデータをロードする(COPYコマンド)
まず事前準備として、コピー用データとIAMロールの設定が必要です。
コピー用データの準備
適当なS3バケットの中に、以下のCSVデータを作成してください。
sale_id,product,amount,sale_date
1,ノートPC,98000.00,2026-01-15
2,マウス,3500.00,2026-01-16
3,キーボード,12000.00,2026-02-01 ファイル名はなんでもOKです。今回は「redshiftdata/202601_sales.csv」としておきました。
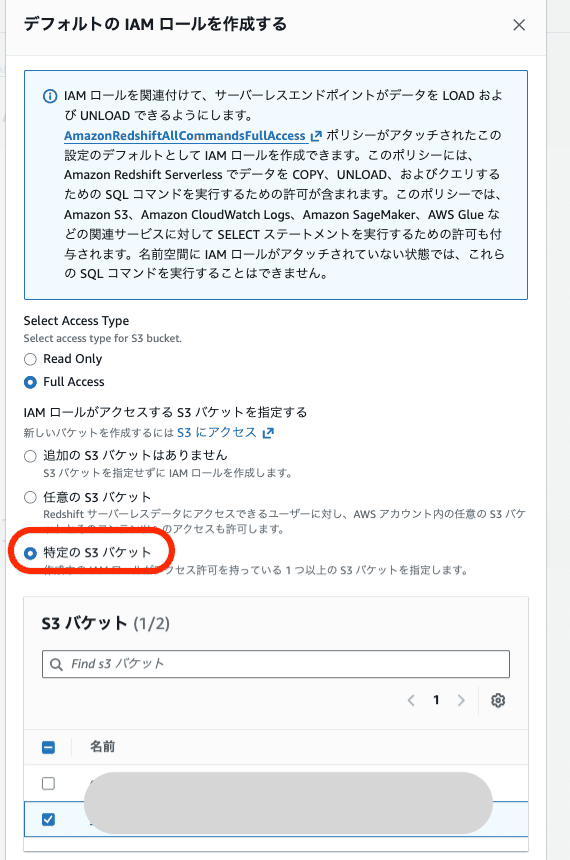
デフォルトIAMロールの作成
S3のデータをRedshiftに取り込む前に、IAMロールの設定が必要です。
Serverlessのコンソールから
- 名前空間の設定から名前空間を選択
- セキュリティと暗号化タブに切り替え
- IAMロールの管理をクリック
- IAMロールを作成をクリック
の順に進み、S3へのアクセス権を持つロールを作成して保存します。
この時、コピー用データを格納したバケットの選択を忘れないようにしてください。
データのロード
ロールの準備ができたら、クエリエディタV2で以下のクエリを実行してください。
CREATE TABLEしてCOPYコマンドでデータをロードしてくれます。
CREATE TABLE sales (
sale_id INT,
product VARCHAR(100),
amount DECIMAL(10,2),
sale_date DATE
);
COPY sales
FROM 's3://mybucket/redshiftdata/'
IAM_ROLE default
FORMAT AS CSV
IGNOREHEADER 1;IAM_ROLE defaultと書くと、先ほど作成したデフォルトのIAMロールを自動で参照してくれます。
④ クエリを実行する
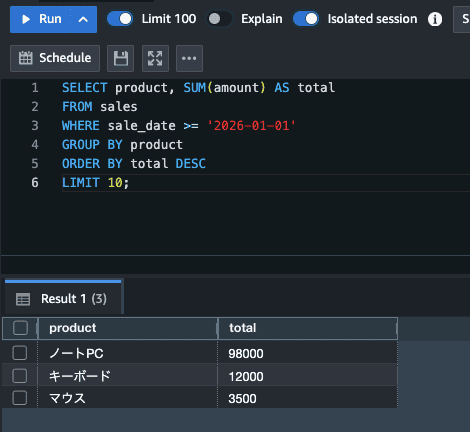
データがロードできたら、あとは普通のSQLです。
SELECT product, SUM(amount) AS total
FROM sales
WHERE sale_date >= '2026-01-01'
GROUP BY product
ORDER BY total DESC
LIMIT 10;クエリエディタV2はコード補完や実行履歴の管理もできるため、開発中の操作性も良さそうですね。
なお、実際の本番環境ではJDBCドライバを使ってBIツールやアプリケーションから接続する形になります。
⑤ リソースのお掃除
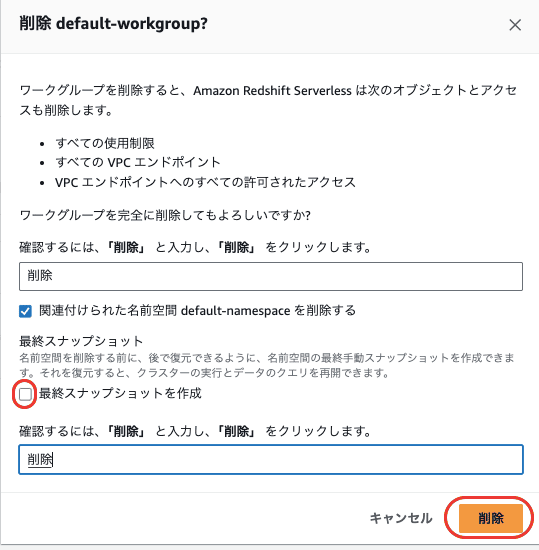
作成したリソースは忘れずに削除しておいてくださいね。
| 順番 | リソース | 削除場所 | 備考 |
|---|---|---|---|
| 1 | ワークグループ | Serverless コンソール | ネームスペースも同時に削除できます |
| 2 | ネームスペース | Serverless コンソール | スナップショットにチェックが入っていると、S3に残り続けるので注意してください |
| 3 | S3バケット | S3コンソール | |
| 4 | IAMロール | IAM コンソール |
分析基盤の「核」を知る
Amazon Redshiftは、
と、データ分析基盤の中心に据えるサービスです。
AthenaがS3への「その場クエリ」だとすれば、Redshiftは「ちゃんとした分析基盤を作る」ときの選択肢になります。
GlueでS3にETLしたデータをRedshiftにロードして、QuickSightで可視化する
というのがAWSのデータ分析スタックの定番構成です。
Glue・Athena・Redshiftの3つが頭に入ると、AWSでどうデータを扱うかの全体像がかなりクリアになるはずです。

AWSを基礎から学ぶなら、RaiseTechが近道。

