
AWSのデータ分析を語るとき、RedshiftやGlueの名前はよく出てきますが、Amazon Athena も外せないサービスのひとつですよね。
S3に置いたデータをそのままSQLで分析できる
シンプルに聞こえますが、この手軽さが実務では最強のツールとなります。
この記事では
に加え
実際の始め方やクエリの実行など、設定方法を分かりやすく解説したいと思います。
「なんとなく知ってるけど触ったことはない」という方が、Athenaを始めるきっかけになれば嬉しいです。
そもそも何ができるの?
Amazon Athenaは、S3に保存したデータに直接SQLクエリを実行できるサービスです。
「サーバーレスのインタラクティブクエリサービス」と呼ばれており、データを別のデータベースに移したり、ETL処理でテーブルを作ったりする必要がありません。
対応しているファイル形式も幅広く、
などをそのままクエリできます。
S3バケットにログファイルが積み上がっているような環境でも、すぐにSQLで集計・分析できるのが大きな強みです。
さらっと書いてますが、この環境自分で構築すると大変ですよね。ありがたいサービスです。
裏側ではApache Prestoをベースにした分散クエリエンジンが動いており、大量データの並列処理が強みです。
パフォーマンスも素晴らしく、テラバイト規模のデータでも数秒〜数十秒でクエリ結果が返ってくることもあります。
しかも、サーバーのセットアップやクラスター管理は一切不要で、クエリを投げるだけで動いてくれる優れもの。
また、AWS Glueのデータカタログと統合されているため、Glueで登録したテーブル定義をそのままAthenaで使えます。
「GlueでS3のデータをカタログ化→Athenaでクエリ」という組み合わせはデータ分析の定番構成ではないでしょうか。
どんな時に使うの?
Athenaが特に活躍するシーンをご紹介します。
もちろん向いていない場面もあります。
毎秒大量のトランザクションが発生するようなOLTP用途にはRDSやAuroraの方が適しています。
また、同じデータに対して何度も繰り返しクエリを実行するなら、Redshiftにデータをロードした方がコスト効率が良くなる場合もあるでしょう。
「S3にあるデータをSQLで探索・集計したい」という用途に最も適したサービスです。
お金はどのくらいかかるの?
Athenaの料金体系は非常にシンプルで、クエリでスキャンしたデータ量に対して課金されます。
| 内容 | 料金 |
|---|---|
| SQLクエリ(東京リージョン) | スキャン1TBあたり$5 |
| 最小課金単位 | クエリごとに10MB |
| DDL(CREATE/DROP等) | 無料 |
| キャンセルされたクエリ | 無料 |
たとえば100GBのデータをフルスキャンした場合は「0.1TB × $5 = 約$0.5(約75円)」です。
小さなクエリなら驚くほど安いのですが、テラバイト規模のデータを毎日フルスキャンしていると費用が積み上がるので注意が必要です。
コストを抑えるためのポイントは主に2つです。
なお「Athenaで170万円請求された」という恐ろしい事例がネット上でも話題になっているようです。
1万円でも手が震えるのに、こんな金額、心臓が止まりそうです。
WHERE句で絞り込んでいてもパーティション設定が不十分だとフルスキャンになることがあるので、大きなデータを扱う場合はパーティション設定もセットで理解しておきましょう。
どうやって設定するの?
Athenaを実際に使えるようにするための手順を、コンソール操作とSQL例を交えてご紹介します。
大きく3ステップです。
① クエリ結果の保存先S3を指定する
AthenaはSQLを実行するたびに結果をS3に保存します。
この保存先が設定されていないと、クエリが実行できませんので、設定を行いましょう。
- 事前にS3バケットを作成しておく
- AWSコンソールでAthenaを開く
- 左側メニュークエリエディタを開く
- クエリ設定タブを開く
- 管理を開き、「クエリ結果の場所」に保存先S3バケットを選択
- 「保存」をクリック
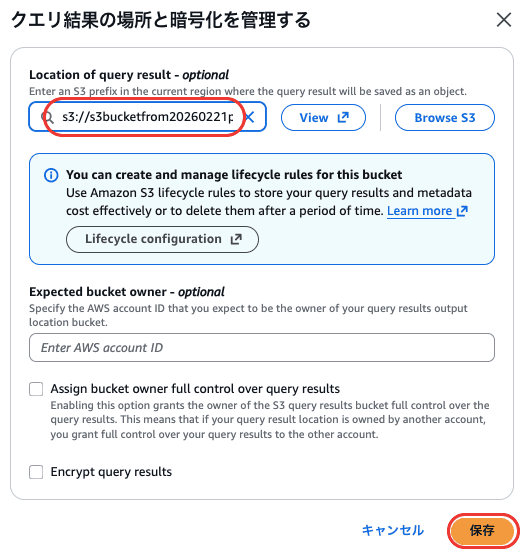
S3バケットは新規作成じゃなくても、既存のバケット内に専用フォルダを作る形でもOKです。
② データカタログにテーブルを登録する
Athenaは「どのS3パスにどんなデータがあるか」をデータカタログ(AWS Glue)に登録することでSQLのテーブルとして認識します。
登録方法は2通りあります。
方法A:Glue Crawlerで自動登録
AWS GlueのCrawler機能を使うと、S3バケットのデータ構造を自動でスキャンしてテーブル定義を作ってくれます。
スキーマが複雑なときや、定期的に構造が変わるデータに向いています。
方法B:AthenaのクエリエディタでDDLを手動実行
シンプルなCSVなら、自分でCREATE TABLE文を書いてAthenaのエディタから実行する方が手軽です。
以下はCSVファイル用のテーブル定義の例です。
CREATE EXTERNAL TABLE my_table (
id STRING,
name STRING,
created_at STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://my-bucket/data/';LOCATIONには実際のS3パスを指定します。
ヘッダー行がある場合は TBLPROPERTIES ('skip.header.line.count'='1') を末尾に追加するとヘッダーを除外できます。
DDL文自体はデータをスキャンしないため、無料で実行することができます。
納得いくまで実行ができるのはありがたいですね。
③ クエリエディタでSQLを実行する
テーブルが登録できたら、あとは普通のSQLを書くだけです。
Athenaコンソールのクエリエディタは同じコンソールで使えます。
左側のパネルにデータベースとテーブルの一覧が表示されるので、テーブルを確認しながらSQLを書けばOKです。
SELECT name, COUNT(*) AS cnt
FROM my_table
WHERE created_at >= '2026-01-01'
GROUP BY name
ORDER BY cnt DESC
LIMIT 10;「クエリを実行」ボタンを押すと数秒〜数十秒で結果が返ってきます。結果はコンソール上で確認できるほか、CSVでダウンロードしたり、S3の保存先に自動保存されます。
S3のデータが、そのまま分析基盤になる
Amazon Athenaの魅力は「S3にデータを置いておくだけで、いつでもSQLで探索できる」というシンプルさにあります。
AWS Glueと組み合わせると、「GlueでデータをS3に整形して保存→AthenaでSQLを投げて分析」という流れが作れます。
この2つを覚えておくと、AWSでのデータ分析基盤の全体像がかなりクリアになりますね。
まずは、試しに自分のS3バケットにCSVを置いてCREATE TABLEを書いてみましょう。
最初の設定さえクリアすれば、Athenaはデータ分析の強い味方になってくれるはずです。

AWSを基礎から学ぶなら、RaiseTechが近道。

